Run ensembling is a technique where, from a single input, multiple runs are generated in parallel. Once all the runs succeed, the best run is selected based on some criteria. This technique is useful in situations such as:
- Taking into account randomness in the model, and using repetitions to get a more reliable result.
- Running the same model with different configurations to obtain the best results.
- Comparing different models to determine which one is the best for a given input.
A normal run looks like the following image:
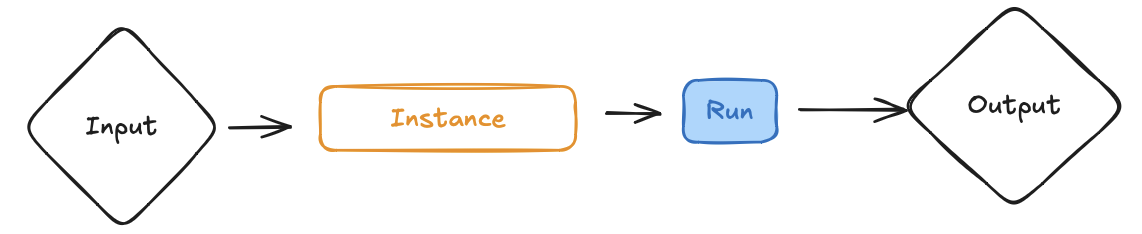
In a normal run, the input is sent to an instance. This creates a unique run within the application. The run is then executed and the results are returned as an output.
An ensemble run works differently, as shown in the following image:
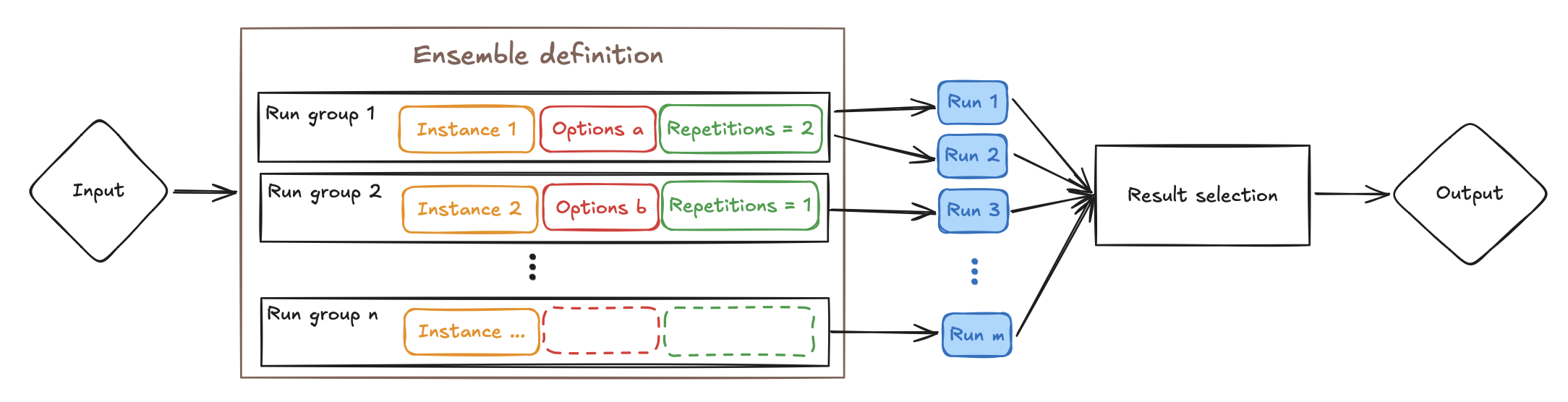
In an ensemble run, the input is processed by an ensemble definition. The ensemble definition contains run groups, and these groups make it possible to create one or more runs from a single group, by means of repetitions.
Once the input is processed by the ensemble definition, one or more runs are created for each of the run groups. All the runs are executed in parallel, and once all the runs succeed, the best run is selected. Finally, the result is returned as an output.
An ensemble run uses the same mechanics as a normal run, this is, it is characterized by a singular run_id and it contains a single input and a single output. The difference is that the ensemble run acts as a parent run that produces multiple child runs.
To work with ensemble runs, please follow these steps:
Understand how it works. This is a detailed overview of how ensemble runs work and how the results are selected.
Create an ensemble definition. Ensemble definitions are meant to be reusable among ensemble runs, and you only need to create them once.
Run with ensembling. Execute an ensemble run.
More information about ensembling can be found in these sections:
Manage ensemble definitions. This is the process of creating, updating, and deleting ensemble definitions.
Ensemble definition schema. This is the schema that defines the structure of an ensemble definition.
How it works
An ensemble run relies on the ensemble definition to create multiple child runs and then select the best one. As such, the ensemble definition is the key component of the ensemble run. The ensemble definition contains two core parts:
- Run groups: These define how to generate runs from a single input.
- Rules: These define how to select the best run from the generated runs.
After all the runs are executed, as defined by the run groups, the rules are evaluated and a single run is selected as the best run.
Run groups
A run group, as its name suggests, is a set of runs. The run group contains an instance which is responsible for running the input. The run group also contains the number of repetitions that will be executed. If the number of repetitions is greater than one, the input will be executed multiple times. A run group can also contain options that are used to configure each run in the group.
Consider the following example of run groups present in an ensemble definition:
As a result, the following 5 runs would be created:
| Run Index | Run Group ID | Instance ID | Options | Repetition ID |
|---|---|---|---|---|
| 1 | run-group-1 | production | {"duration": "30", "threads": "2"} | 1 |
| 2 | run-group-1 | production | {"duration": "30", "threads": "2"} | 2 |
| 3 | run-group-1 | production | {"duration": "30", "threads": "2"} | 3 |
| 4 | run-group-2 | production | {"duration": "20", "threads": "4"} | 1 |
| 5 | run-group-2 | production | {"duration": "20", "threads": "4"} | 2 |
Rules
Rules are used to select the best run from the generated runs. The input before evaluating the rules is a set of runs. The output after evaluating the rules is a single run, which is the best one. Each rule has an index that gives the rules a priority order. The logic works as follows:
Rules are ordered by their index.
For the first rule: all the runs are sorted based on the
objectiveandstatistics_pathof the rules. Each run should have a metric that can be extracted from its statistics, based on the path given by the rule’sstatistics_path. If the objective isminimize, the metrics of the runs are sorted in ascending order. If the objective ismaximize, the runs are sorted in descending order based on the metric.The first run of the sorted list of runs is the best one for the first rule. For the remaining runs, the ones that fall within a
toleranceof the first one (the best) are picked as well. A run falls within the tolerance if thedelta(or difference) is less than or equal to the rule’svalue. The difference can beabsoluteorrelative.Here are the formulas used for calculating the
delta, depending on therule.Consider the following.
absolutedifference andminimizeobjective:absolutedifference andmaximizeobjective:relativedifference andminimizeobjective:relativedifference andmaximizeobjective:
If there are no runs within the
tolerance, it means that the search is complete and we found the best run.If there is more than one run within the tolerance of the best one, move on to the next rule. Now, the list of competing runs is the best run and the runs that fell within the tolerance.
The next rule is applied in the same way as the previous one.
After all rules are applied, if there is more than one run left, the best one is picked randomly.
All the runs must have a status_v2 of succeeded and must contain JSON statistics in order to be successfully evaluated by the rules.
Consider the following example. You have the following list of child runs that were created for the parent ensemble run:
Here are some cases of applying different rules and what the expected outcome would be.
Please note that the path in the statistics_path is specified using JSONPath notation.
Case 1
- Best run:
run-1 - Explanation: After evaluating
rule-1, there were no runs that fell within the tolerance.run-2has a difference of500-298=202andrun-3has a difference of500-325=175. The tolerance is anabsolutevalue of100, so no other runs are within the tolerance ofrun-1.
- Best run:
Case 2
- Best run:
run-3 - Explanation: After evaluating
rule-1,run-1is the best given that it has the highest.result.value. The tolerance is now180, which means thatrun-2is not within the tolerance (as it has a difference of500-298=202), butrun-3is, with a difference of500-325=175. The incumbent runs are nowrun-1andrun-3. Forrule-2,run-3is the best run because it has the lowest number of unplanned stops, and the rule says tominimizethe metric. Therelativedifference forrun-1, with respect torun-3, is(4-2)/2=1, which is greater than the tolerance of0.2. Given thatrun-1does not fall within the tolerance, and onlyrun-3remains, it is selected as the best.
- Best run:
Case 3
- Best run:
run-2 - Explanation: After evaluating
rule-1,run-1is the best given that it has the highest.result.value. The tolerance is now250, which means that bothrun-2andrun-3are within the tolerance, withabsolutedifferences of500-298=202and500-325=175, respectively. The incumbent runs are nowrun-1,run-2, andrun-3. Forrule-2,run-3is the best run because it has the lowest number of unplanned stops, and the rule says tominimizethe metric. The tolerance is now0.7, which means that onlyrun-2is within the tolerance, with arelativedifference of(3-2)/2=0.5.run-1has arelativedifference of(4-2)/2=1, which is greater than the tolerance. The incumbent runs are nowrun-2andrun-3. For the last rule,rule-3,run-2is the best run because it has the lowestmax_travel_duration, and the rule says tominimizethe metric. Therelativedifference forrun-3, with respect torun-2, is(7200-1200)/1200=5, which is greater than the tolerance of0.8. Given that onlyrun-2remains, it is selected as the best.
- Best run:
Case 4
- Best run:
run-2orrun-3 - Explanation: This is almost the same example as showcased in Case 3. The only difference is the
tolerancevalueofrule-3, which is now7.5. Given that forrule-3,run-2was the best run, and therelativedifference ofrun-3was5, we can now see thatrun-3is within the tolerance of7.5. As such, all the rules were evaluated, and the best run is selected randomly betweenrun-2andrun-3.
- Best run:
Create an ensemble definition
Note, all requests must be authenticated with Bearer Authentication. Make sure your request has a header containing your Nextmv Cloud API key, as such:
- Key:
Authorization - Value:
Bearer <YOUR-API-KEY>
The ensemble definition contains the properties that make it possible to create one or more runs from a single input. You only need to create an ensemble definition once and use the definition when creating ensemble runs.
To create an ensemble definition, use the following endpoint:
Create an ensemble definition.
Create an ensemble definition.
The request body must be a JSON object that follows the ensemble definition schema.
Run with ensembling
Once an ensemble definition is created, and you have the definition_id, you can use it to run with ensembling. To start an ensemble run, the process is very similar to starting a normal run. The difference lies in the configuration that is sent in the request body.
To run with ensembling, the run_type object must be present in the configuration:
Note that the definition_id must be the ID of an existing ensemble definition. The ensemble definition is meant to be reusable among ensemble runs.
This configuration is used within the context of the endpoint for starting a new application run.
New application run.
Create new application run.
You can poll or use webhooks to await for the ensemble run to be finished, signaled by a status_v2 of succeeded. Once the ensemble run is finished, you can get the results.
When using the endpoint to get the results of an esemble run, the results for the best child run are returned. This allows you to use the same workflow of normal runs with the ensemble runs.
Get run result.
Get the result of a run.
To get the ensemble run result, which is the detailed information about how the best run was chosen, you can use the following endpoint.
Get ensemble run results.
Get ensemble run results specified by application and run ID.
Manage ensemble definitions
To manage the ensemble definitions, you can use the following endpoints:
List existing ensemble definitions.
GEThttps://api.cloud.nextmv.io/v1/applications/{application_id}/ensemblesList all ensemble definitions.
List all ensemble definitions for an application.
Get an ensemble definition.
GEThttps://api.cloud.nextmv.io/v1/applications/{application_id}/ensembles/{ensemble_id}Get ensemble definition.
Get ensemble definition specified by application and ensemble ID.
Update an ensemble definition.
PATCHhttps://api.cloud.nextmv.io/v1/applications/{application_id}/ensembles/{ensemble_id}Update an ensemble definition.
Update an ensemble definition.
Delete an ensemble definition.
DELETEhttps://api.cloud.nextmv.io/v1/applications/{application_id}/ensembles/{ensemble_id}Delete ensemble definition.
Delete an ensemble definition.
Ensemble definition schema
Here is an example of an ensemble definition:
The ensemble definition follows this schema:
| Field name | Required | Data type | Description |
|---|---|---|---|
id | Yes | string | A unique identifier for the ensemble definition. |
name | Yes | string | A human-readable name for the ensemble definition. |
description | No | string | An optional description of the ensemble definition. |
run_groups | Yes | array of run_group | An array of run groups that define how to generate runs. |
rules | Yes | array of rule | An ordered array of rules that define how to select the best run. |
A run_group determines how to create a group of runs from a single input. It follows this schema:
| Field name | Required | Data type | Description |
|---|---|---|---|
id | Yes | string | A unique identifier for the run group. |
instance_id | Yes | string | The instance that will process the input. |
options | No | object | The options that will be used to configure the run. These options are applied on top of the instance’s options. |
repetitions | Yes | integer | The number of times the input will be executed. |
A rule performs an evaluation on a set of runs and chooses the runs that best fulfill the given objective on the specified metric. It follows this schema:
| Field name | Required | Data type | Description |
|---|---|---|---|
id | Yes | string | A unique identifier for the rule. |
statistics_path | Yes | string | The JSONPath path to the metric contained in the .statistics of the run. |
tolerance | Yes | tolerance | The tolerance that will be used to compare the metric values. |
objective | Yes | string | The objective that will be used to select the best run. Must be one of: maximize, minimize. |
index | Yes | integer | The index of the rule. The index gives different rules a priority order. |
The tolerance specifies how to compare a run against the best run in a rule. It follows this schema:
| Field name | Required | Data type | Description |
|---|---|---|---|
type | Yes | string | The type of tolerance. Must be one of: absolute, relative. |
value | Yes | float | The value of the tolerance. |