


Have you ever ordered sushi? It goes like this: you’re hungry, you pull out your phone, press a few buttons on a delivery app, and 30 minutes later, sushi appears, and you’re happy and full. That is the lifespan of a sushi roll as you’ve experienced it. But there are many logistical decisions happening (very quickly) behind the scenes for you — and hundreds or thousands, or even more, customers.
This post will walk through the decisions made for real-time delivery, along with anecdotes from real-time optimization experiences to offer insight into the value of developing, deploying, and managing these systems as software components.
Three sushi delivery scenarios: perfect, likely, worst
In a perfect world, you’ve placed your order at 12:00 on a delivery app. You get a message saying it will be delivered in the next 30 to 35 minutes. Fantastic, you’ll finish up a few emails, ready your kitchen table, and lunch will have arrived.
Meanwhile, a series of well-timed events are unfolding. After the restaurant accepts your order, they begin preparing your food. A few blocks away, an idling courier gets assigned to your order and starts heading to the restaurant. As the courier arrives, opens the door, and strolls in, your packaged up sushi order is being placed on the counter. The courier grabs your order, heads to your address, and delivers your order as you requested and within the time you expected. 👌

What’s more likely to happen, is the restaurant is super busy with a bunch of walk-ins when you place your order (it’s peak lunchtime after all). Because of this, they start preparing your order later than expected. But the courier is already on the way, unaware of the prep time delay, and arrives at the restaurant. Now, the courier must wait 15 minutes to pick up the order and then deliver it to you. You get your sushi 10 minutes after your expected time, complaining about the service, but finishing that roll just in time before the next meeting.

In the worst case scenario, when the darker forces conspire against your sushi delivery, let’s say the restaurant isn’t just super busy, but that it’s pouring rain outside. In this scenario, your order prep time starts later than expected, but now the delivery platform is having a hard time finding a courier. People are rejecting the order because they don’t want to get wet and be in the cold. Only until 12:45 does someone accept the order to deliver — and they’re on the other side of town. In this case, the sushi is now waiting for the courier to arrive, pick up the order, and deliver it to you an hour later than expected. At this point, you’re beyond angry as you reluctantly eat down your sushi rolls and rage uninstall the app.
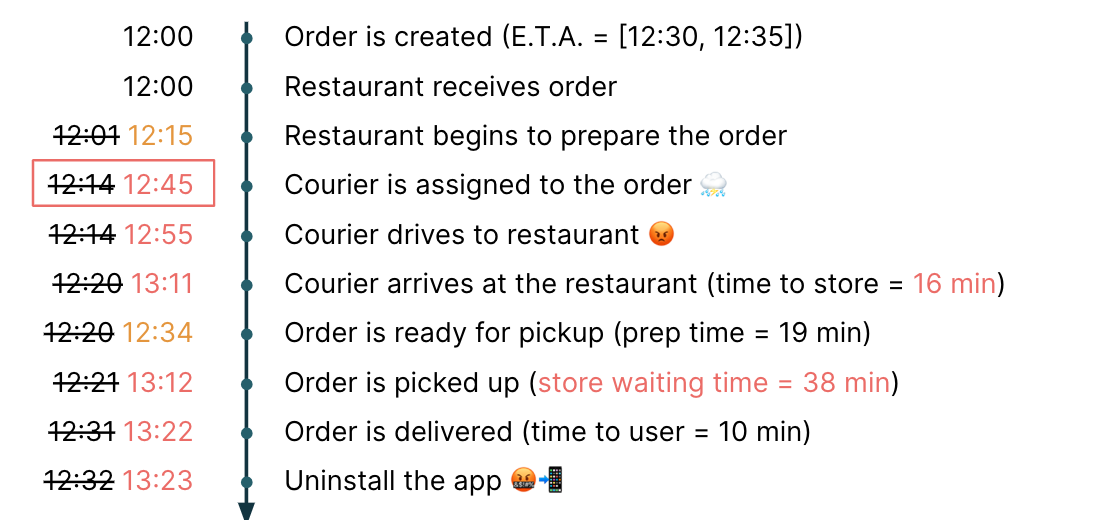
It’s likely you’ve experienced one or all of these scenarios — the euphoria and the blind frustration — so what’s powering all of it?
The technical pieces behind the sushi order decision making
From order placed to order delivered, there are real-time optimization processes at play behind the scenes. At each step in the process, there are different decisions being taken along the way:
- Which restaurant does your sushi order get assigned to? Big restaurant names might have multiple franchises within delivery distance.
- Which courier gets assigned to your sushi order? The closest courier is not always the best choice, as there are factors such as vehicle type and bundling of other orders that have to be considered.
- Which route should the courier take to complete the order? The shortest route, distance-wise, is not always the best, as you have to take into account traffic, road-work, and human knowledge.
As a consumer, you press some buttons, magic happens, and sushi arrives! But what are the technical considerations that help make the series of decisions that help deliver your sushi?
To answer this, let’s use the first question in our list above (“Which restaurant does your sushi order get assigned to?”) and consider the inputs and outputs. First, you need to understand your inputs at a business level and a technology level. At the business level, there are considerations for location of your users (or counter-to-door time), preparation time for your orders, and estimated waiting time for preparation time to start. Having (or lacking) these data points will inform what is the most appropriate decision-making algorithm to use. For instance, if all you know are the locations of restaurants and users, applying a bi-partite matching algorithm, implemented with an open source solver such as HiGHS, is a good starting point. On the other hand, if you have a robust set of predictions for information such as waiting time before preparation starts, preparation time, traffic, courier availability and volume of upcoming orders; it would be best to apply sequential decision making strategies with stochastic inputs.
At the technology level, you need to evaluate where your input data is coming from. Is your data stored in a database? Being streamed on a messaging pipeline? Maybe in the simple case you have to get a JSON payload. This restaurant assignment problem is only one of the many components that make up an intertwined network of services and logic. If the data layer for the input takes up the majority of the compute, it is wise to choose an optimization solution that is fast. Optimizing can be sped up by either simplifying the model or choosing a more suitable solver for the given problem. On the other hand, if preparing the inputs for the assignment problem is a nimble process, then you can spend more time on the model to incorporate more complexity. The idea here is that there is a limited amount of resources (execution time, compute) and you must distribute those resources between data wrangling and solving.
Now, let’s look at the outputs of that first assignment problem. Very rarely, someone will need the solver’s output to the assignment problem represented with some boolean decision variables. You need to work with other modules in the company to transmit the data as it is needed downstream. In modern software systems, the preferred format is normally a JSON payload, but depending on how your service plugs into the rest of the company, the data can be a collection of CSVs or even a set of push notifications. As an analytics professional, your work doesn’t stop when the model is done running. In any optimization, not breaking the system is incredibly important. Let’s say your model is infeasible for some input where there are no restaurants near a customer’s home. The output of your model can not be a code error. Instead, a good alternative might be returning an empty list of assignments and raising an alarm somewhere when this happens.
In general, it’s easy to become overly enthusiastic in modeling and try to represent every possible facet of the business and end up overconstraining a problem that results in frustratingly undesirable solutions. It’s also possible to get too focused on model performance for finding the optimal solution, dramatically increasing the time or compute investment beyond what you really needed.
In on-demand logistics, it often makes sense to solve for the best solution in the time you have. This means you have the freedom to start with simple representations paired with adaptable approaches. In short: Pick your battles. In the case of our restaurant assignment problem, it’s acceptable to start by assigning the nearest restaurant location, make sure there are enough available drivers, and then account for order saturation. And prove out the model from there through systematic testing and iteration — for each logistics question we have to answer.
Real-time optimization systems as part of a larger network
I believe that optimization models should look, feel, and operate like any other software. This means they should be easy to build, test, and deploy. They should be versioned like other software and straightforward to integrate with modern tech stacks and CI/CD workflows. They are also part of a larger network of systems and services, so they also need to be resilient.
Here’s one example of how one real-time optimization system fits into a larger network of software and services:

You have an optimization model that is written in Python and powered by a mixed integer program (MIP) (or other solving paradigm). That model lives in a service that receives input from another service in Go that gets the state of your entities, and fetches data from a SQL database. The model then has two outputs. One involves push notifications to a mobile device. The other path outputs to the core team via Kafka event stream to say that the assignments were made. That event stream gets consumed by a Java service which in turn does some further processing out of your team’s domain. That processing, for example, might be updating the queue of orders that are assigned to each restaurant and applying modifications to the user’s app to signal that the order has been accepted. Although an example like this might be typical in a microservice oriented architecture, a monolith also has different modules that act as black boxes that communicate with each other.
As you can see, it is important for the decision service to always be responsive, otherwise you risk a chain reaction that would make the downstream services fail as well. For example, you could have a backup model that’s a greedy heuristic (or alternate solver) running in the background in shadow mode. If the primary MIP fails and can’t find a solution, you have a fallback for making assignments and your operation can still run. Another alternative would be to have an alarm configured which would be raised if there are empty assignments, and thus bringing a human into the loop.
Technical solutions that make the modeling possible
As analytics professionals working in real-time optimization, you’re ideally spending the majority of your time on modeling logistics or optimization problems. In reality, a lot of time often gets diverted to untangling the technical pieces that make the modeling process more efficient for you and more valuable to the business. The technical pieces to consider here are:
Deployment and CI/CD
Models need to run in production somewhere. Ideally, you have reliable, scalable infrastructure that provides you with a clear path to deployment and set of API endpoints for running, managing, and testing your decision models. Integrating with CI/CD and Git-based workflows allows you to ship higher quality code to that production infrastructure faster and with greater visibility across teams.
Monitoring and Management
When did your model fail to run? What is the status of the current run? Which version is production pointing to? This is just a sampling of questions any decision modeler is likely to face within their teams. Having the observability tools and processes to quickly answer these questions and make transparent changes are important for maximizing your time spent on modeling.
Something else to consider when managing a model, is that it may not work well in all regions. For example, searching for a hamburger in Manhattan in New York City is very different from searching for a hamburger in Fairfax, Virginia, which is a suburban area that is dramatically less dense. Your model parameters should not be the same for every region.
Visualization and Collaboration
They say a picture is worth a thousand words — and is often the medium that creates shared understanding across many types of stakeholders. The ecosystem of visualization tools is growing. Steamlit is one option that’s gaining visibility in the decision science space.
Testing and Experimentation
Ideally, you have a model testing and experimentation framework that runs on remote infrastructure. There are two ways to think about decision model testing: 1) historical tests using known, representative input sets such as acceptance and scenario tests, and 2) online tests using real-time data inputs such as shadow and switchback tests. As you progress through each type of testing, you establish more confidence in the model you’ve developed.
To close out this section, I’ll share a personal story. Previously, I worked at Rappi, a large Latin American on-demand delivery platform. I deployed a new parameter to the routing model that routed couriers in a particular region. I introduced a new parameter to the model and deployed the new code to production, in one of the regions that had fewer orders. Simple enough, right? Well, about 30 minutes into my lunch I get a phone call from another country. It was the VP of engineering for fulfillment (my boss). "Sebas, we have a spike of unassigned orders and I see a lot of error logs, do you know what’s up?" In that exact moment it hit me: the new parameter was reading from a database and I never added it, so the code was throwing an exception. Fortunately, the impact wasn’t too bad and we recovered.
But I carry that experience with me to this day. In an ideal situation, I’d have tested the integration and interaction of my code with the database to give me more confidence in deploying to production.
The takeaway (sushi aside) from this post
As a decision modeler looking to be valuable to an on-demand business, you want to demonstrate repeatability and predictability. More bluntly: you want to be boring. You don’t want everyone’s eyes on you all the time because the algorithm is making weird decisions. Testing is key here. Offline testing helps you evaluate changes, reproduce results, and tune performance. When you’re ready for production, online testing helps you understand the real interaction of your model under production conditions. From there, you’ve built up confidence that your next model rollout won’t break production. Treating your optimization model as an engineered software component makes this possible — and keeps your focus on building more and better models, not more decision tools.





